Low Precision Training with Kahan Summation¶
While training models in low precision (Float16 or BFloat16) usually differs from training in full precision (Float32) or mixed precision, optimi optimizers can match the performance of mixed precision when training in pure BFloat16 by using Kahan summation1.
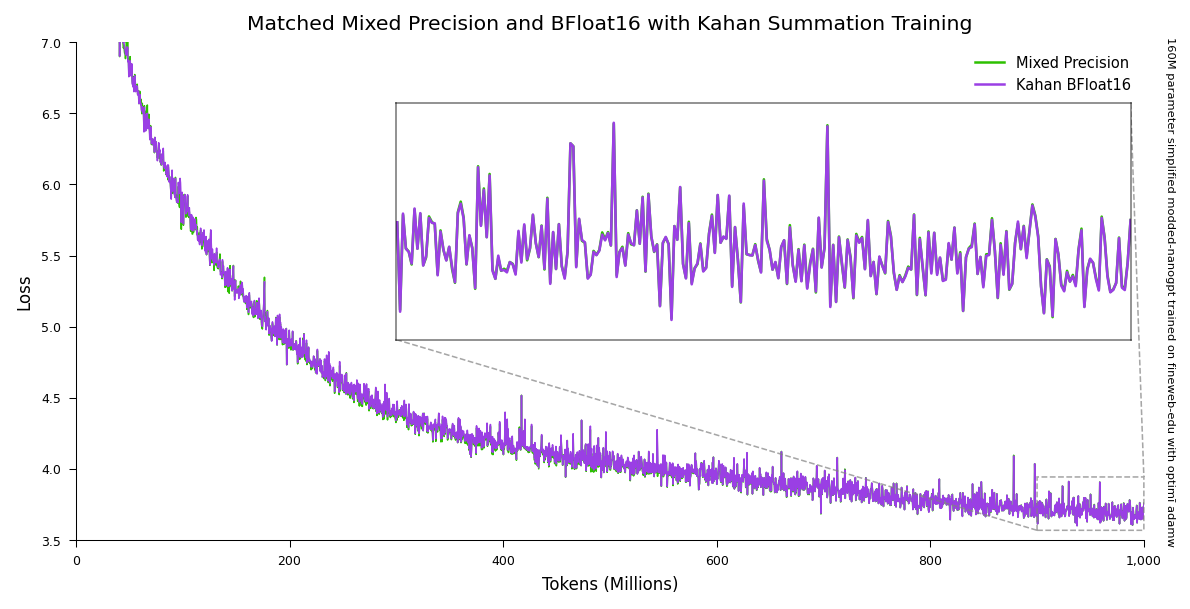
Training in low precision reduces non-activation memory usage up to ~46 percent and can increase training speed up to ~30 percent relative to mixed precision training.
Using Kahan summation for accurate BFloat16 training is as simple as replacing a PyTorch optimizer with its optimi equivalent and casting the model to BFloat16 instead of using mixed precision.
Tip: Keep a Few Layers in Float32
When training in BFloat16, keep rotary buffers, rotary calculations, and token embedding layers in Float32, as these benefit from full precision. This results in a small memory increase and speed decrease, but can help guarantee equivalent results with mixed precision training.
optimi's to_low_precision simplifies keeping these layers in Float32.
By default, optimi optimizers will automatically use Kahan summation for any layers training in low precision. Set kahan_sum=False to disable.
Mixed Precision¶
While implementations details can differ, mixed precision works by running a forward pass in low precision, automatically switching to full precision per layer as needed, and then accumulating gradients during the backward pass in Float32. The optimizer step runs in full precision.
The hybrid precision setup of mixed precision enables the faster operations and lower memory usage of low precision while keeping the convergence of full precision.
Kahan Summation¶
Kahan summation2 is a technique to reduce the numerical error of adding multiple low precision numbers by accumulating errors in a separate compensation buffer. The addition of the compensation buffer increases the effective summation precision by the precision of the compensation buffer.
Using Kahan summation to improve low precision model training was first introduced by Zamirai et al in Revisiting BFloat16 Training. Zamirai et al discovered the primary source of numerical error from low precision training is during the optimizer’s model weight update step. They add Kahan summation to the SGD & AdamW weight update steps to reduce the update’s numerical inaccuracy, increasing low precision training to the equivalent of full precision training across tested models.
Note: Implementation Inspired by TorchDistX
optimi’s Kahan summation implementation was directly inspired by TorchDistX’s AnyPrecisionAdamW optimizer.
For more details, see the algorithm and explanation sections.
Memory Savings¶
Training in pure BFloat16 with Kahan summation can reduce non-activation training memory usage up to 37 to 45 percent when using an Adam optimizer, as Table 1 shows below.
| Buffer | Mixed Precision | BFloat16 + Kahan Sum | BFloat16 |
|---|---|---|---|
| BF16 Model Weights (if used) | 2 bytes | 2 bytes | 2 bytes |
| FP32 Model Weights | 4 bytes | - | - |
| Gradients | 4 bytes | 2 bytes | 2 bytes |
| Distributed Buffer (optional) | 4 bytes | 2 bytes | 2 bytes |
| Momentum | 4 bytes | 2 bytes | 2 bytes |
| Variance | 4 bytes | 2 bytes | 2 bytes |
| Kahan Compensation | - | 2 bytes | - |
| Total | 16-22 bytes | 10-12 bytes | 8-10 bytes |
Calculating the total memory savings depends on activations and batch size, mixed precision implementation details, and the optimizer used, to name a few variables.
optimi reduces potential extra memory overhead of Kahan summation by reusing the gradient buffer for temporary variables.
Training Speedup¶
Training in BFloat16 instead of mixed precision results in up to a ~10% speedup on a single GPU, up to a ~20% speedup with two GPUs, and up to a ~30% speedup with multiple GPUs3.
Example¶
Using Kahan summation with an optimi optimizer only requires a casting a model and optionally input into low precision (BFloat16 or Float16). Since Kahan summation is applied layer by layer, it works for models with standard and low precision weights.
import torch
from torch import nn
from optimi import AdamW
# create or cast some model layers in low precision (bfloat16)
model = nn.Linear(20, 1, dtype=torch.bfloat16)
# initialize any optmi optimizer with low precsion parameters
# Kahan summation is enabled since some model layers are bfloat16
opt = AdamW(model.parameters(), lr=1e-3)
# forward and backward, casting input to bfloat16 if needed
loss = model(torch.randn(20, dtype=torch.bfloat16))
loss.backward()
# optimizer step automatically uses Kahan summation for low precision layers
opt.step()
opt.zero_grad()
To disable Kahan Summation pass kahan_summation=False on optimizer initialization.
Algorithm¶
SGD with Kahan summation.
This shows the optimi implementation of Kahan summation optimizers, which is equivalent to the Revisiting BFloat16 Training formulation.
Explanation¶
optimi optimizers with Kahan summation modify the base optimizers by introducing a compensation buffer \(k\) to mitigate numerical errors from training in low precision.
Using SGD as an example, the SGD parameter update is straightforward: \(\textcolor{#009ddb}{\bm{\theta}_t ← \bm{\theta}_{t-1} - \gamma_t\bm{g}_t}\). Where \(\theta\) is the model parameters at steps \(t-1\) and \(t\), and \(\gamma_t\) and \(g_t\) are the learning rate and gradient at step \(t\), respectively.
SGD with Kahan summation expands the single update model parameter step to three steps:
- \(\textcolor{#9a3fe4}{\bm{u}_t ← \bm{k}_{t-1} - \gamma_t\bm{g}_t}\): First, an intermediate update \(u_t\) is computed from the prior compensation buffer \(k_{t-1}\). This allows the current parameter update to account for any precision errors in last parameter update.
- \(\textcolor{#9a3fe4}{\bm{\theta}_t ← \bm{\theta}_{t-1} + \bm{u}_t}\): The parameter update uses the error compensated update \(u_t\) instead of directly subtracting \(\gamma_t g_t\).
- \(\textcolor{#9a3fe4}{\bm{k}_t ← \bm{u}_t + (\bm{\theta}_{t-1} - \bm{\theta}_t)}\): Finally, the compensation buffer is updated to stores the difference between the intended update (\(u_t\)) and the actual change in the parameters \((\theta_{t-1} - \theta_t)\), capturing any errors from operating in low precision numerical types.
These Kahan summation steps allow optimi optimizers to nearly reach or match the performance of mixed precision when training in low precision.
-
Plot shows a simplified modded-nanogpt 160M model, trained on 1B FineWeb-Edu tokens, with RoPE and token embedding layers in Float32 and all other layers in BFloat16. ↩
-
Also known as Kahan–Babuška summation or compensated summation. ↩
-
Pure BFloat16 training can increase distributed training speed more then single GPU due to the halved bandwidth cost. Observed results may differ based on GPU connectivity and effectiveness of computation-communication overlap. Maximum observed speed increase was on consumer GPUs. ↩