Triton Optimizer Implementations¶
optimi's vertically fused Triton optimizers are faster than PyTorch's fused Cuda optimizers, and nearly as fast as PyTorch's compiled optimizers without any hassle1.
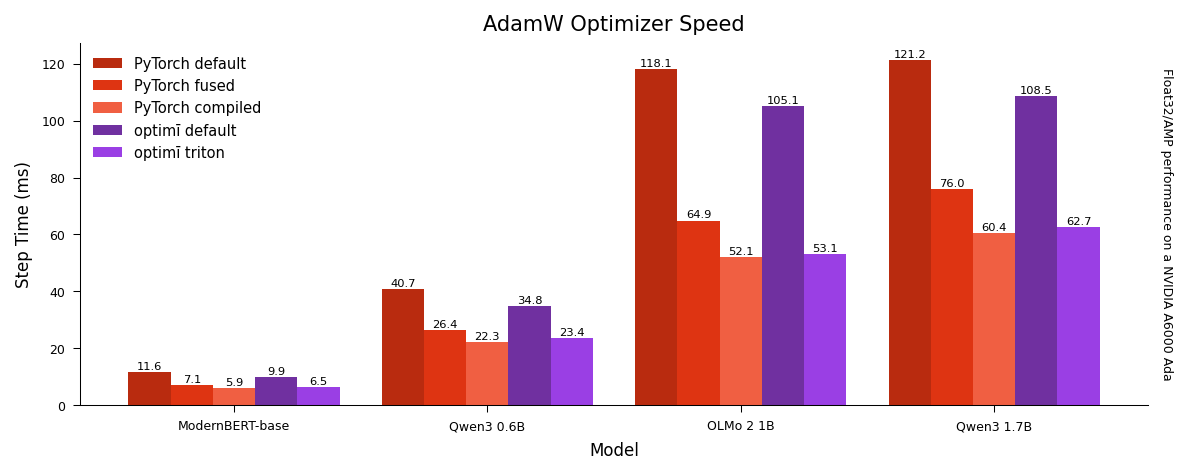
If unspecified triton=None and foreach=None, optimi will use the Triton implementation by default if training on a modern NVIDIA, AMD, or Intel GPU2.
Note: Triton Optimizers Requires PyTorch 2.6+
optimi’s Triton implementations require PyTorch 2.6 or newer. It's recommended to use the latest version of PyTorch and Triton.
The Triton backend is compatible with gradient release and optimizer accumulation.
Example¶
optimi will use the Triton backend by default on a supported GPU. To disable this behavior set triton=False when initializing the optimizer.
import torch
from torch import nn
from optimi import AdamW
# create model
model = nn.Linear(20, 1, device="cuda")
# models on a supported GPU will default to `triton=True`
opt = AdamW(model.parameters(), lr=1e-3)
# or initialize any optimi optimizer with `triton=True`
opt = AdamW(model.parameters(), lr=1e-3, triton=True)
# forward and backward
loss = model(torch.randn(20))
loss.backward()
# optimizer step is the Triton implementation
opt.step()
opt.zero_grad()
-
Compiling optimizers requires change to the training loop which might not be supported by your training framework of choice, and any dynamic hyperparemters such as the learning rate need to be passed as Tensors or the optimizer will recompile every step. ↩
-
A GPU supporting bfloat16. Ampere or newer (A100 or RTX 3000 series), or any supported AMD or Intel GPU. ↩